
Introduction
Have you ever found yourself drowning in a sea of articles, PDFs, and web pages that you want to read but simply don’t have the time for? I recently built a solution that tackles this exact problem: an intelligent URL content summarizer that can extract and summarize content from any web page, text file, or PDF document using the power of AWS Bedrock and Claude 3.
In this article, I’ll walk you through how I created a serverless content summarization service that’s both cost-effective and incredibly easy to use. Whether you’re a developer looking to build similar AI-powered tools or someone curious about practical applications of large language models, this guide will show you exactly how to build your own content summarizer from scratch.
TL;DR
I built a serverless URL content summarizer using:
- AWS Bedrock with Claude 3 Haiku for AI-powered summarization
- TypeScript and Node.js for the backend logic
- AWS Lambda and API Gateway for serverless deployment
- AWS CDK for infrastructure as code
The service accepts any URL (HTML, text, or PDF), extracts the content, and returns an intelligent summary. It’s cost-effective, scalable, and can be deployed in minutes.
Repository: https://github.com/pedraohenrique/text-summarizer-bedrock
Architecture Overview
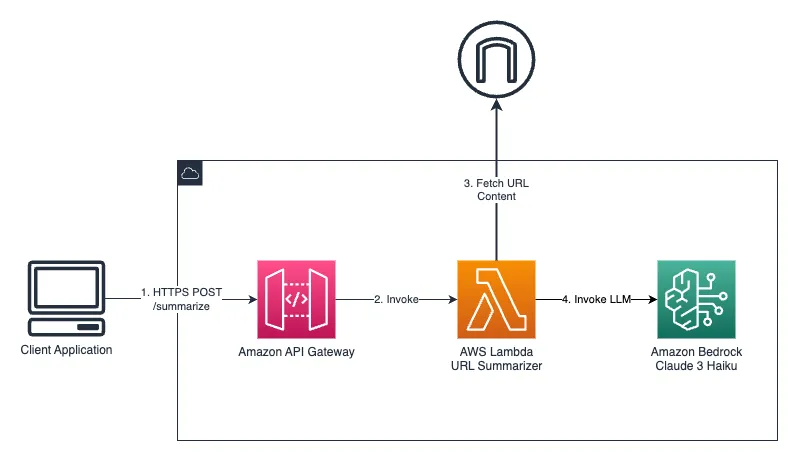
Building the Solution
Step 1: Setting Up Content Extraction
The first challenge was handling different content types. I created specialized extractors for each format:
HTML Content: Using Cheerio to parse HTML and extract meaningful content while removing navigation, ads, and styling elements.
PDF Documents: Leveraging the pdf-parse library to extract text from PDF files.
Plain Text: Direct processing for simple text content.
Each extractor implements a common interface, making it easy to add support for new content types in the future.
Step 2: Integrating AWS Bedrock for Summarization
For the AI-powered summarization, I chose Claude 3 Haiku from Anthropic via AWS Bedrock. Here’s why this was the perfect choice:
- Cost-effective: Haiku offers excellent performance at a fraction of the cost of larger models
- Fast processing: Quick response times perfect for real-time summarization
- High quality: Produces coherent, well-structured summaries
- Managed service: No need to worry about model hosting or scaling
The integration handles prompt engineering to ensure consistent, high-quality summaries with configurable length limits.
Step 3: Building the Serverless API
I wrapped everything in a Lambda function with API Gateway for a completely serverless architecture:
// Example API usage
POST /summarize
{
"url": "https://example.com/article",
"maxLength": 500
}
// Response
{
"url": "https://example.com/article",
"contentType": "html",
"summary": "This article discusses...",
"originalLength": 5000,
"summaryLength": 450
}The API includes proper error handling, CORS support, and input validation to ensure reliability and security.
Step 4: Infrastructure as Code with AWS CDK
Using AWS CDK, I defined the entire infrastructure in TypeScript:
- Lambda function with appropriate memory and timeout settings
- API Gateway with CORS configuration
- IAM roles with minimal required permissions for Bedrock access
- CloudFormation outputs for easy endpoint discovery
This approach ensures reproducible deployments and makes it easy to manage the infrastructure alongside the application code.
Step 5: Deployment and Testing
The deployment process is straightforward:
npm install
npm run build
npm run deployOnce deployed, you can test the API with any HTTP client or integrate it into your applications.
How to Use It
Using the summarizer is incredibly simple. Send a POST request to the /summarize endpoint with a URL and optional maximum length:
curl -X POST https://your-api-url/summarize \
-H "Content-Type: application/json" \
-d '{
"url": "https://aws.amazon.com/blogs/aws/new-amazon-bedrock/",
"maxLength": 300
}'The service will fetch the content, extract the text, and return a concise summary along with metadata about the original content.
Possible Extensions
This foundation opens up numerous possibilities for enhancement:
Multi-language Support: Add translation capabilities to summarize content in different languages.
Batch Processing: Extend to handle multiple URLs simultaneously for research workflows.
Custom Prompts: Allow users to specify different summarization styles (bullet points, executive summary, technical overview).
Content Caching: Implement caching to avoid re-processing the same URLs.
Webhook Integration: Add webhook support for asynchronous processing of large documents.
Authentication: Integrate with AWS Cognito for user management and usage tracking.
Analytics Dashboard: Build a frontend to track usage patterns and popular content.
Conclusion
Building this URL content summarizer was an excellent way to explore the practical applications of AWS Bedrock while creating something genuinely useful. The combination of serverless architecture and AI-powered summarization creates a powerful, scalable solution that can handle real-world content processing needs.
What I love most about this project is how it demonstrates the democratization of AI capabilities. With just a few hundred lines of TypeScript and some AWS services, we can build sophisticated AI-powered applications that would have required significant infrastructure and expertise just a few years ago.
The serverless approach means you only pay for what you use, making it cost-effective for both personal projects and production applications. The modular design makes it easy to extend and customize for specific use cases.
Whether you’re looking to build content curation tools, research assistants, or just want to stay on top of your reading list, this architecture provides a solid foundation for AI-powered content processing.
Have you built similar AI-powered tools? I’d love to hear about your experiences and any creative extensions you might envision for this type of service. Feel free to reach out or contribute to the project!
The complete source code for this project is available on GitHub. Feel free to fork, extend, and adapt it for your own use cases. Happy coding!